みなさん初めまして見習いデータサイエンティストのりゅうと申します。
今回は2016年に登場してからkaggleを中心に関心が高まっているフレームワークLightGBMを試してみた結果をまとめます。
使うデータはsklearnのdatasetsに練習用として用意されているload_wineです。
LightGBMとは
今回の記事では仕組みの詳細は割愛させていただきますが、LightGBMとは決定木と勾配ブースティングを組み合わせた機械学習フレームワークです。
決定木を直列に繋ぎ合わせて複数回行なっていく中で、1つ前の決定木でうまく分類仕切れなかった箇所を重点的に次の決定木では分類していくイメージです。
一般的にLightGBMの特徴としては下記が挙げられます。
- モデル訓練に掛かる時間が短い
- メモリを抑えることが可能
- 精度が高い
- 過学習しやすい
- 大規模なデータセットも訓練可能
ざっくりいうと過学習に気をつけていれば軽くて精度が高い最強のフレームワークです!
データの取得
まずは必要なライブラリ等のimportとデータの取得を行なっていきます。
import numpy as np
import pandas as pd
# lightGBM
import lightgbm
# sklearnの練習データであるdatasetsの中のload_wineを読み込む
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
# モデルの評価モジュールであるsklearnのmetrics
# sklearn.metricsモジュールには、スコア関数、パフォーマンスメトリック、ペアワイズメトリック、および距離計算が含まれる。rmspeなどが有名
from sklearn.metrics import accuracy_score, roc_auc_score, confusion_matrix, precision_score, recall_score
# 警告を非表示にする
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
%matplotlib inline記述の通り今回データはsklearnに練習用として用意されているワインのデータload_wineを使用します。
# 練習データの可視化
data = load_wine()
data
データを覗いてみるとtargetが0,1,2で割り振られているのが確認できます。今回はこの0,1,2の3つのクラスターに分ける作業をしていきましょう。
特徴量データと教師データを作成する
ダウンロードしたload_wineはディクショナリ型で入っているためpandasを使ってDataFrameにしていきます。
X = pd.DataFrame(data['data'], columns=data['feature_names'])
# X = pd.DataFrame(data.data, columns=data.feature_names) の書き方でもOK
y = pd.DataFrame(data['target'])
# y = pd.DataFrame(data.target) の書き方でもOK
display(X.shape)
display(y.shape)(178, 13), (178, 1)
全体のデータ数は178個と少し少なめです。今回は特に前処理やEDAを行わず、このままの状態でLightGBMにデータを渡します。
トレーニングデータと検証用データの分割
全体178のうち80%をトレーニングデータとして使用し、残りの20%のデータで正解率を出すように記述していきます。
scikit-learnのtrain_test_splitを使って下記のように設定してみましょう。
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)- X_train:特徴量トレーニングデータ
- X_val:特徴量検証用データ
- y_train:ターゲットトレーニングデータ
- y_val:ターゲット検証用データ
- test_size=0.2:それぞれX_val, y_valを全体の20%に分割されるように設定(178*0.2 = 35.6 ~= 36)
- random_state=42:分け方が毎回統一されるようにrandom_stateを設定。42はおまじないの数字(万物の答え)
178*0.8 = 142個のデータでX_train,y_trainを学習させ、そのモデルを使ってX_valから取得した検証用データ(y_predと後に命名)とy_val(実際の分類の答え)がどれくらいの正解率かを確かめる作業を行います。
LightGBMのパラメータを用意
LightGBMを使うにあたって決定木の深さはどうするのか、ブースティングの回数は何回かなどの学習させる際のパラメータを設定してあげる必要があります。
最適なパラメータを自動で求めてくれる手法もありますが、今回は下記のように適当に割り振ります。
# lgbmのパラメータをチェック(引数max_depthだけ設定)
lgb_clf = lightgbm.LGBMClassifier(
# 典型的な勾配ブースティング
boosting_type='gbdt',
class_weight=None,
# もしfeature_fractionが1.0より小さければ、LightGBMは毎回ランダムに特徴量を部分的に抽出
# 0.8の場合LightGBMは訓練前に特徴量の80%を選択す
colsample_bytree=1.0,
importance_type='split',
# 収縮測度
learning_rate=0.1,
# 決定木の深さ
max_depth=5,
# 1つの葉のデータの最小個数。オーバーフィッティングへの対処に用いる。
min_child_samples=20,
min_child_weight=0.001,
min_split_gain=0.0,
# ブースティングの回数
n_estimators=100,
# LightGBMに用いるスレッド数
n_jobs=-1,
# 1つの木の最大葉数
num_leaves=31,
objective=None,
random_state=42,
reg_alpha=0.0,
reg_lambda=0.0,
silent=True,
subsample=1.0,
subsample_for_bin=200000,
subsample_freq=0)
lgb_clf.fit(X_train, y_train)特にモデルの推測精度に影響が大きいパラーメータは以下の3つです。
num_leaves
直訳すると葉の数です。num_leavesは決定木の複雑度を調整するパラメータでもっとも重要度が高いとも言われています。
num_leavesの値が高すぎると過学習となり、低すぎると未学習になってしまうため、チューニングの際は要注意です。
num_leavesを調整する場合はmax_depth(決定木の深さ)のパラメータと一緒に調整すると良いです。
min_data_in_leaf
min_data_in_leafは決定木の葉の最小データ数を指定するパラメータです。
値が高いと決定木が深く育つ(樹形図がどんどん下に作られてしまう)のを抑えるため過学習防ぐが、逆に未学習となる場合もあるので注意が必要です。
min_data_in_leafは訓練データのレコード数とnum_leavesに大きく影響されるためここも合わせて見るようにしましょう。
max_depth
決定木の深さを指定するハイパーパラメータです。単体で調整するよりも、num_leavesなど他のハイパーパラメータとのバランスを考えながら調整するのが良いとされています。
予測値と正解率を計算
上記のパラメータで学習させた結果を取得し、実際のデータと比較してその正解率を見てみましょう。
今回は学習したX_valの値36個と実際のデータy_valの値36個を比較した時にどれくらいの精度で正しいクラスターに分類出来ていたかを見ます。
# 予測値と正解率を計算
y_pred = lgb_clf.predict(X_val)
accuracy_score(y_val, y_pred)1.0
なんと今回はaccuracy_scoreが1.0!100%の精度でした!
間違いと思って他を調べてみましたが、データ数が今回のように少ない時は稀に精度100%を出してくれるそうです。
どの特徴量が重要かを可視化してみる
LightGBMのもう一つすごい点は、どの特徴量が効いているかを可視化して取得してくれることです。
下記のように記述して特に効いていた特徴量を見てみましょう。
# 特徴量の重要度の可視化
lightgbm.plot_importance(lgb_clf)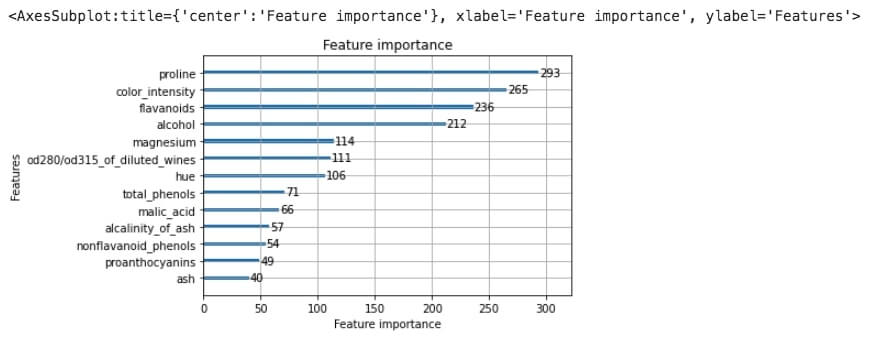
このような形で特徴量と重要度をグラフ化してくれます。
今回一番効いていたのは「proline(α-アミノ酸の1つ)」という特徴量でした。これらを参考にすることでよりチューニングも捗ると思いますのでぜひこちらも試してみてください。
LightGBM load_wine まとめ
今回はsklearnの練習データload_wineをLightGBMによって分類してみました。
調べながら作業を行なったため、自分自身完全に分かりきっている訳ではありませんが、今後実務やkaggleの中で間違いなく使っていくだろうと確信するほど優れたフレームワークであることは間違い無いのでこれからもLightGBMについての学習を続けていこうと思います。
最後までご覧いただきありがとうございました!