
皆さんこんにちは週7フリーランスのりゅうです。
今回からはデータ分析で使うライブラリについて学んでいきます。第一弾として科学計算の基礎、Numpyについてです。
Numpyのインポート
まずはJupyter環境でNumpyをこれから使うぞ!と宣言してみます。
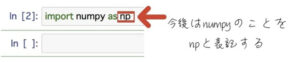
「as 〇〇」として自分の好きなように名前を変えられます。今回は「np」と命名。
これによって今後は「np.機能名」と表記するとJupyter環境でNumpyが動いてくれます。
配列操作をやってみる
まずはNumpyに慣れるためにも基礎的な配列について勉強していきます。

「自分で勝手につけた名前(今回は"data") = np.機能名」という書き方です。
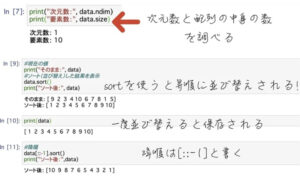
dataという変数を自分で作り、「np.array」の形でどのような配列かを指定してあげます。
([])の中に適当に1から10の整数をバラバラに書き込んで定義すると、「data」と打つだけで定義した変数が表示されるようになりました。
ポイント
配列を作るのは「array」というメソッドでしたが、それ以外にどのようなものがあるのかを調べるには、「変数.」(変数 + ドット)の後にtabキーを押します。
次元数や配列の要素の数を調べたり、並べ替えをすることも出来ます。
(デフォルトで昇順。降順は[::-1]と記載)
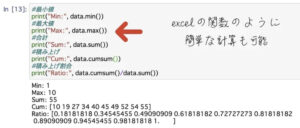
Excelの関数と同じようなメソッドを使って最小値・最大値などを調べたり、配列内の計算をすることも可能です。
乱数について
今度は乱数についてです。だんだんデータ分析っぽい感じになってきましたね。
乱数とは規則性のないデタラメな数のことをいい、データ分析では収集したデータをランダムに分離したりばらつきを与える時によく使うようです。
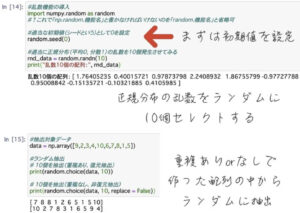
まずは毎回「np.random.機能名」と書くのが面倒なので「random.機能名」だけで済むようにimportします。
次に0を初期値として設定し、正規分布の乱数をランダムに10個試しに取得してみます。
出力する際は、重複有りなのか無しなのかも選択できるためこちらも覚えておきましょう。
行列について
続いては行列。先ほど登場したarrayを再び使用します。
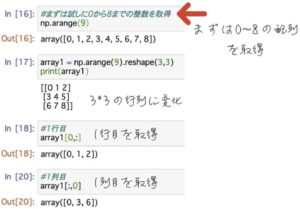
適当に0~8の整数列を作り、それを3*3の行列に変化させます。
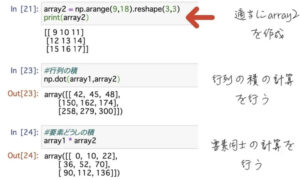
array2として9~17の自然数列も作成します。
行列の計算の時に注意しなくてはならないのが、行列*行列の計算をしたいのか、行列の要素どうしを計算させたいのかで書き方が違うという点です。
行列*行列の計算を行う場合はdotを使います。要素どうしの掛け算はシンプルに1行目1列目同士をかけた結果をそれぞれのポジションに表示する計算となります。
最後におまけとして要素が0や1のみの行列の作り方を載せておきます。

(2,3)というのは2行3列の行列を作成するという意味です。ビット数や整数・小数等も指定することができます。
今回はだいぶ駆け足でしたが、Numpyの基礎的な動きについて勉強しました!次回はScipyについて勉強していきます。
最後までご視聴ありがとうございました!