
皆さんこんにちは週7フリーランスのりゅうです。
前回、前々回とNumpy/Scipyについて基礎的な部分を学んできました。今回はPandasの基本的な動作について勉強していきます。
まずはPandasのライブラリのインポート
早速インポートしていきましょう。
一次元の配列を扱う時のSeriesライブラリと二次元の配列を扱う時のDataFrameライブラリをインポートします。
Seriesを使ってみよう
PandasのベースはNumpyのarrayらしいので簡単な例を使って勉強していきます。
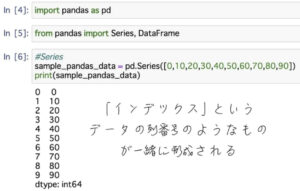
上の画像のように、データの中身と、中身を特定する番号(インデックス)が表示されました。
下記のようにインデックスを編集したり別々に取得することも可能です。

DataFrameを使ってみよう
今度は二次元配列を取得してみましょう。それぞれの列で異なるdtype(データ型)を持たせることもできます。
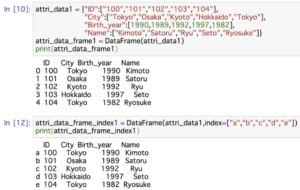
DataFrameもSeries同様インデックスの編集が可能です。
今まではprint()の形で記述してきましたが、Jupyter環境では変数をそのまま記述することで表記することもできます。
その場合、勝手にSeriesオブジェクトやDataFrameオブジェクトであることが認識され、表らしい形で出力されます。
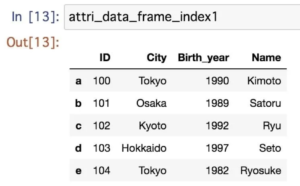
ここでも行列操作
DataFrameでは様々な行列操作が可能です。

行と列の入れ替え、特定の列の取り出し、などなど。
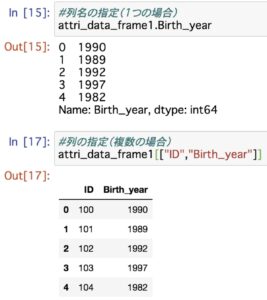
データの抽出をやってみよう
DataFrameオブジェクトでは、特的の条件を満たすデータだけを取り出したり複数のデータを結合する操作も行えます。
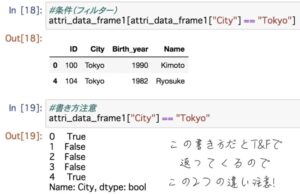
TrueかFalseで取得する書き方もあるのでこの2つの違いには注意です。複数条件ももちろん可能です。
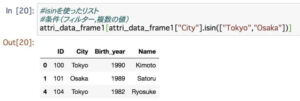
データの削除や結合をしてみよう
DataFrameオブジェクトどうしは結合できるようになっています。

行削除:1つ目の引数に削除したい行のインデックスをリストとして指定。axisパラメータには「0」を指定。
列削除:1つ目の引数に削除したい列名をリストとして指定。axisパラメータには「1」を指定。
続いて結合です。今回は新たに作ったattri_data2を結合させてみましょう。
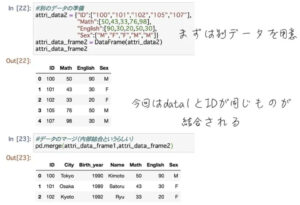
デーブル同士に共通するデータがあった場合(今回はID)、被っていたデータのみが列が結合された形で取得されます。
データの集計
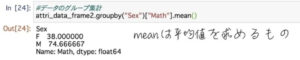
groupbyメソッドを使って特定の列を軸にデータを集計してみます。
値のソートについて
SeriesやDataFrameではデータやインデックスをベースにソートすることが可能です。(ソートとは並べ替えです)
ソート用に適当にデータを準備します。
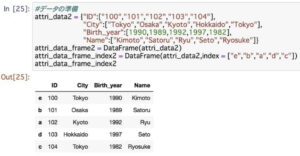
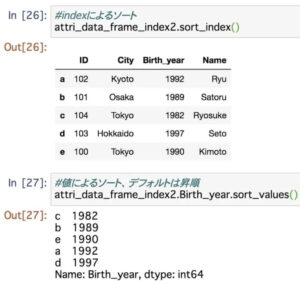
インデックスでソートをすることもデータの値でソートをすることも可能です。
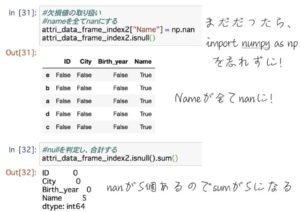
nan(null)の判定
データ分析では、データの欠損が生じることが多々あります。
そのまま計算してしまうと平均等がうまく計算されなくなってしまうため、除外するなどしてあげましょう。
今回はPandasについて勉強しました。表などが登場し、だんだんそれらしくなってきましたね。
次回はグラフなどを扱うMatplotlibについて勉強していきます。
今回も最後まで読んでいただきありがとうございました!